This feature allows you check various indications of dimension health. Currently, this feature:
- Checks that attribute relationships hold true according to the data. For instance, if a Subcategory is actually a part of more than one Category, that attribute relationship should not be used. Usually, fixing this problem (described in more detail below) involves revisiting the definition of the keys for each attribute.
- Checks the definition of attribute key to determine uniqueness. Particularly, this check determines if a particular key has more than one name.
- Checks whether any obvious attribute relationships are missing. Particularly, this checks whether any attributes have a subset of the keys of other attributes, but are not related.
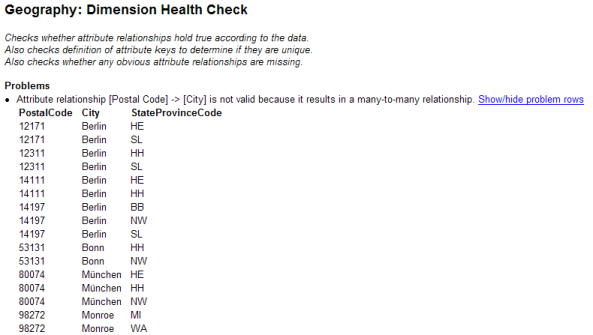
Note: If you run a dimension health check on either the Customer or the Geography dimension in Adventure Works, it tells you “Attribute relationship [Postal Code] -> [City] is not valid because it results in a many-to-many relationship”. This is, in fact, a mistake. The key for the [Postal Code] attribute should include the StateProvinceCode column in addition to the PostalCode and City columns. Below is a screenshot of the Dimension Health Check report for the Geography dimension:
Note: If you run a dimension health check on the Date dimension in Adventure Works, it tells you “Attribute [Day of Week] has a subset of the keys of attribute [Day Name]. Therefore, those attributes can be related which is preferable to leaving [Day of Week] related directly to the key.” This change could, in fact, be made, though it is not required. Clicking the “Change attribute relationship” link will make this change for you.

Note: In the 1.1.0.1 release, only SQL Server is supported as a datasource. The 1.2 release supports Oracle as a datasource also. The 1.3.0.8 release supports Teradata as a datasource also.
Fixing Problems Identified By Dimension Health Check
There are several ways you can fix invalid attribute relationships surfaced by Dimension Health Check. The decision really depends on what the user will expect to see:
- If the attribute is part of a natural user-defined hierarchy, then make the key a composite key by adding the keys of the attributes above it in the hierarchy. Make sure the attribute itself is AttributeHierarchyVisible=false so that users won’t look at it by itself (because if they do, they’ll think there are duplicate members).
- e.g. If your problem is that a Month relates to multiple years, then change the key on Month to a composite key of Month/Year (or a single key which is the same cardinality as that composite key, such as one in the form of YYYYMM).
- If users need to see the problem attribute as part of a hierarchy (so that the child shows up separately under both parents) and additionally as an attribute (so that the child is grouped into one total) then do the prior bullet point from above but rename that hidden attribute “AttributeName For Hierarchy”, then add a new attribute without the composite key and leave the new attribute visible. Rerun Dimension Health Check and it will double check that your second attribute is a property of the first.
- e.g. If your problem is that a Subcategory relates to multiple categories, then make the key a composite key of Category/Subcategory then rename your Subcategory attribute to “Subcategory for Hierarchy” then set it to AttributeHierarchyVisible=false. Next, add a new Subcategory attribute with a single key of Subcategory then make that new attribute a property of the old attribute. Category should be related to “Subcategory for Hierarchy,” but Category should be unrelated to Subcategory.
- Change which attributes are related to each other to avoid the problem.
- e.g. If your problem is that Zipcode relates to multiple cities, then you may want to make Zipcode and City both directly related to the key since the data simply doesn’t support this relationship.
Limitations
- Currently only SQL Server, Oracle, and Teradata are the supported data sources.
- Currently secondary data sources (which occur when the primary data source for the DSV is one data source, but the DSV table in question comes from a second data source) are supported starting with release 1.6.5 as long as the dimension in question is not a snowflake dimension spanning multiple data tables from multiple data sources.